Silent data corruption (SDC), sometimes called bit rot or silent data errors (SDEs), refers to errors in data that are not detected by standard error-checking mechanisms, leading to potentially significant data loss or incorrect calculations. SDCs can lead to inaccurate training, incorrect predictions, and unreliable performance. Detecting SDC requires specialized techniques and tools.
SDCs can be transient or random. Transient SDCs can be caused by radiation events like neutrinos or alpha particles. Neutrinos and alpha particles are difficult to predict and even more challenging to stop. Fortunately, they are also rare and do not significantly contribute to SDCs in data centers and most AI systems.
The bigger and more serious source of SDCs are permanent hardware faults resulting from defects in ICs. That’s the focus of this article.
SDCs are quantified in defects per million (DPM) and often exist at the time of fabrication, hence the moniker “time 0 defects.” The vanishingly small feature sizes of advanced ICs can exacerbate the appearance of SDCs, making it impossible to eliminate them.
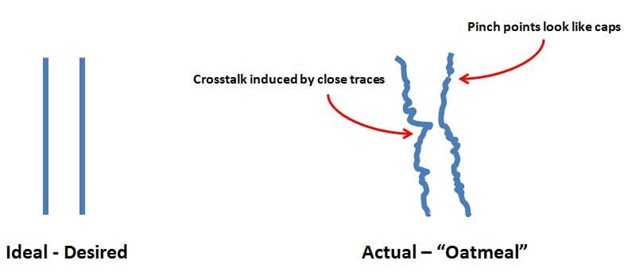
Especially in a high-performance IC, small defects and marginalities at numerous points in a device can result in inconsistent results. The patterning on ICs like DRAMs, CPUs, and GPUs is not perfect. Even slight irregularities in size, shape, and spacing can result in SDCs. This is sometimes referred to as the “oatmeal” effect (Figure 1).
Of course, the various types of ICs vulnerable to SDCs are not used in isolation; they are parts of larger systems. A recent study utilized performance data from a fleet of cloud data centers to examine the correlation between SDCs in memory and other system components. Some of the findings included (Figure 2):
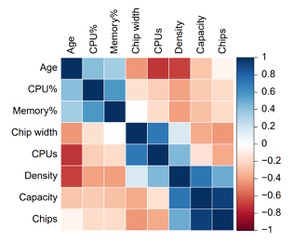
- Memory errors follow a Pareto distribution where a large portion of the effect comes from a small number of sources.
- Non-DRAM failures from the memory controller and channel contribute most of the errors.
- Newer, higher-density DRAMs have higher failure rates.
- DIMMs with fewer chips and lower transfer widths have lower error rates.
- CPU and memory utilization rates, CPU% and Memory%, respectively, are correlated with overall server failure rates.
Detection and mitigation
Detection and mitigation of SDCs is challenging once the ICs are installed in systems. Some defects only occur under specific combinations of factors like temperature, voltage, frequency, and instruction sequences.
In one case, it was observed that 1% of servers were responsible for 97.8% of all correctable errors. One way to mitigate the impact of SDCs is to use redundancy and fault-tolerant architectures, where multiple systems or processors verify the results and validate the data.
That can be expensive and slow overall system operation. Another approach is to identify potentially faulty chips before they are integrated into systems.
For example, Intel’s Data Center Diagnostics Tool (DCDiag) uses multiple mechanisms to identify SDC. It’s based on repeatedly performing an operation or calculation and confirming a correct outcome.
Since these tests explicitly confirm the correctness of every calculation, they have improved the identification of defective parts that cause SDC. Some of the tests include confirming the accuracy of core-to-core and socket-to-socket communications and running complex floating-point, integer, and data manipulation instructions.
The Open Compute Project (OCP) recently established its Server Component Resilience Workstream in response to the increasing challenges of SDC. This workstream focuses on research into hardware-caused SDC and the development of effective detection and mitigation tools. Initial members involved in the workstream include AMD, ARM, Google, Intel, Meta, Microsoft, and NVIDIA.
Summary
With the growing complexity of AI training and models and the shrinking feature sizes of advanced ICs, SDC is a growing problem. The leading cause of SDC is so-called “time zero defects” in hardware that occur during IC fabrication. That increases the challenges with detecting and mitigating its effects. Recently, the OCP established an industry-wide workstream to develop effective tools for dealing with SDC.
References
Computing’s Hidden Menace: The OCP Takes Action Against Silent Data Corruption (SDC), Open Compute Project
Data Center Silent Data Errors: Implications to Artificial Intelligence Workloads & Mitigations, Intel
Detecting silent errors in the wild: Combining two novel approaches to quickly detect silent data corruptions at scale, Engineering at Meta
Examining Silent Data Corruption: A Lurking, Persistent Problem in Computing, Synopsys
Revisiting Memory Errors in Large-Scale Production Data Centers: Analysis and Modeling of New Trends from the Field, Meta Research
Silent Data Corruption, Google
Silent Data Corruption: A Survey Article, Asset
Silent Data Corruptions: Microarchitectural Perspectives, IEEE Computer Society
Silent Data Errors: Sources, Detection, and Modeling, IEEE
EEWorld related content
What interconnects are used with memory for HPC and AI?
What determines the size of the dataset needed to train an AI?
What is the HPC memory wall and how can you climb over it?
What tools are there to reduce AI power consumption?
What’s the difference between GPUs and TPUs for AI processing?

Leave a Reply