
Sensors for touch, vision are on the leading-edge of robotics developments. Sensors enable robots to gather information about the environment, determine how the environment may be changing, and provide the data to determine the appropriate response to any changes. Sensor information can be used to improve performance of the task at hand, or it can provide warnings about safety concerns or potential malfunctions.
In robot systems, tactile sensors are being developed to complement visual systems. Robots are being designed to interact with a variety of objects using precision handling and dexterity similar to that of a human hand. While a vision system can provide important information about an object, vision is not capable of measuring mechanical properties such as texture, stiffness, weight, coefficient of friction, and so on.
Efforts toward development of prosthetic hands for humans is expected to lead to improved tactile sensors for robots. Current robotic and prosthetic hands provide less tactile information than a human hand, but that is changing. A European research consortium has developed a prosthetic hand called SmartHand which enables patients to write, type on a keyboard, play piano, and perform other fine motions. SmartHand has sensors that provide the patient a sense of feeling in its fingertips.
The SynTouch Toccare Haptic Measurement System repeatedly and precisely senses a surface in a way that correlates directly to human perception, quantifying the results consistently across “15 dimensions of touch.” It provides information to quantify subjective tactile concepts such as “softness.” Using spider plots and analytics the system can provide characterizations of 15 haptic dimensions within five categories: Compliance (deformability), Friction, Texture, Adhesion, and Thermal. The analysis employs a database of touch that includes profiles of thousands of materials ranging from nonwovens, cosmetics, apparel, consumer electronics, and more.
International Federation of Robotics innovation winners
An intelligent gripper named RG2-FT was one of the finalists in last year’s 16th Award for Innovation and Entrepreneurship in Robotics & Automation (IERA) from the International Federation of Robotics. Developed by OnRobot, the RG2-FT has fingertips that can “feel” and pick up delicate materials such as thin glass or test samples and can pass them along to humans.

The RG2-FT gripper is designed to perform delicate work activities, even without knowing the exact location of the piece. The gripper uses advanced proximity and force-torque sensors to mimic the fingertip sensibility of a human hand. The company compares it with humans picking up a pencil with closed eyes: “Proximity sensors ‘feel’ the object until the grip is perfect. The gripper then controls its force precisely. It picks up the object, safely passes it on to a human, knowing to let go when handing over.”
Advances in robot vision are complementing the advances in robot touch capabilities. The second finalist for last year’s IERA awards from the International Federation of Robotics was the “MotionCan-3D” from Photoneo. According to the company, “Our camera is able to inspect objects moving as fast as 140 kilometers per hour. Its qualities are useful in various fields: for example, in e commerce and logistics, for object sorting and autonomous delivery systems. The camera also helps in food processing and waste sorting as well as harvesting in agriculture. Thanks to accurate machine vision, robots can also analyze objects with high resolution images, which is important in quality control.”
Computer vision, machine vision and robot vision
Computer vision is an advanced form of image processing. Image processing is primarily interested in converting or improving the quality of an image to make it suited for additional processing or analysis. Computer vision is the process of extracting information from an image and “understanding” the image contents.

Computer vision combined with machine learning, can be used to enable pattern recognition. For example, computer vision can be used to detect features and information about an image, such as the sizes and colors of individual parts. That information is then analyzed using machine learning algorithms to determine if specific parts are faulty based on learned knowledge of what a good part looks like.
Machine vision is sometimes used interchangeably with robot vision, but they are not identical. Machine vision is used in less complex applications such as the parts inspection described above. Robot vision is one input to a more complex system. Robot vision can incorporate kinematics, and reference frame calibration to help determine how the robot interacts with its environment. This is sometimes referred to as “visual servoing” and involves controlling the motion of a robot using the feedback of the robot’s position and environment including the use of a vision sensor.
Machine learning and artificial intelligence, combined with robot vision, can enable a mobile robot to determine its location on a map and navigate its environment. The combination of machine learning and robot vision is improving robot capabilities in identifying, picking and passing objects, and in autonomous mobility.
Identifying, picking, and passing objects can be enabled by a combination of 3D vision, tactile sensors, and machine learning. Robots equipped with vision capability can identify objects regardless of their location or orientation. And 3D vision systems enable robots to detect objects partially hidden behind other objects. Using a combination of vision, tactile sensors and machine learning, a robot can teach itself how to pick up a new object and apply the correct level of force. Robots are currently limited to picking up relatively stiff or rigid objects. Work is underway to improve the ability of robots to interact with and grip items packaged in bags or plastic wrapping, or that have irregular and variable shapes.
Autonomous mobility combining machine learning and robot vision is enabling robots to navigate in complex environments. Earlier generations of mobile robots (called automated guided vehicles, “AGVs”) were been very limited in their ability to move around an environment. They were programmed to execute a specific set of motions, often guided by signals such as magnetic strips or lasers from devices installed specifically for that purpose. AGVs are limited in their ability to respond to unexpected obstacles; they can stop, but are not able to identify an alternative route.
Combining machine learning and robot vision results in the ability for a robot to go from one point to another autonomously. The robot uses a preprogrammed map of the environment, or can build a map in real time. It can identify its location within an environment, plan a path to the desired endpoint, sensing obstacles it encounters and changing its planned path in real time. And robots need to be able to deal with changes in the environment as well as identify and track moving objects.
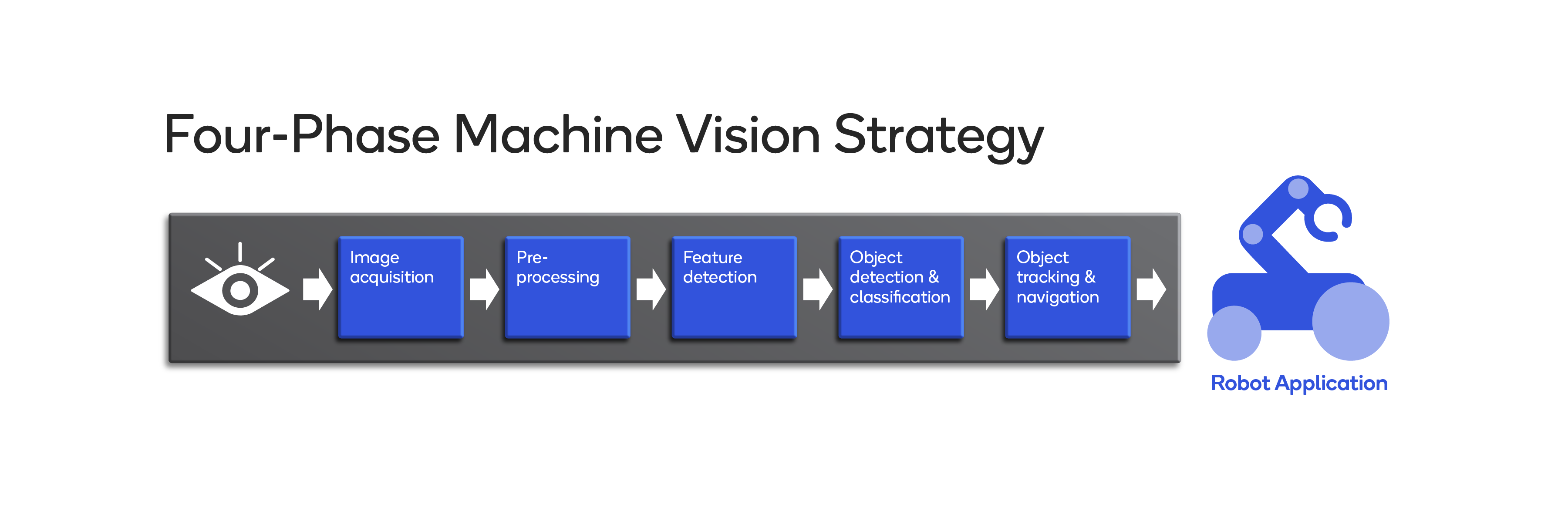
Researchers at Qualcomm have proposed a four-phase strategy to overcome the challenges faced by developers of robot vision systems. This strategy is specifically designed to produce data that can be used to control robot servos, make decisions about the environment and enable other high-level robot tasks and analysis. The four phases include:
- Image acquisition from various sensors and cameras, then using image processing techniques to convert the visual data into more usable formats.
- Using computer vision and machine vision algorithms to extract information from the image such as the locations and sizes of corners and edges.
- Employing machine learning to classify and identify objects.
- Track and navigate the identified objects. This includes tracking objects across time and analyzing changing views of the environment as the robot moves.
Autonomous mobile robots with machine learning capabilities and sensors for vision and/or touch are finding commercial applications in a variety of areas such as:
- Retrieving and transporting materials in factories, warehouses, hospitals and other environments.
- Using vision sensors or RFID scanners to perform inventory management tasks.
- Working in dangerous or hazardous environments ranging from radiation-contaminated sites to deep-sea and outer space.
- And more mundane tasks such as cleaning commercial spaces or the hulls of ships.
As shown, adding sensory capabilities such as touch and vision can significantly enhance robot capabilities. Previous FAQs in this series reviewed more general robot characteristics such as “Robot axes of motion, safety and power architectures,” and “Robot software environments and motion control architectures.” The next and final FAQ will review “International performance and safety standards for robots.”
References
A Four-Phase Strategy for Robotic Vision Processing, Qualcomm
Artificial intelligence in robots, International Federation of Robotics
Robot Vision vs Computer Vision: What’s the Difference?, Robotiq
Robotic sensing, Wikipedia
Sensor technology that replicates human touch, Syntouch




Leave a Reply